

Meta has released the latest entry in its Llama series of open source generative AI models: Llama 3. Or, more accurately, the company has open sourced two models in its new Llama 3 family, with the rest to come at an unspecified future date.
Meta describes the new models — Llama 3 8B, which contains 8 billion parameters, and Llama 3 70B, which contains 70 billion parameters — as a “major leap” compared to the previous-gen Llama models, Llama 2 8B and Llama 2 70B, performance-wise. (Parameters essentially define the skill of an AI model on a problem, like analyzing and generating text; higher-parameter-count models are, generally speaking, more capable than lower-parameter-count models.) In fact, Meta says that, for their respective parameter counts, Llama 3 8B and Llama 3 70B — trained on two custom-built 24,000 GPU clusters — are are among the best-performing generative AI models available today.
That’s quite a claim to make. So how is Meta supporting it? Well, the company points to the Llama 3 models’ scores on popular AI benchmarks like MMLU (which attempts to measure knowledge), ARC (which attempts to measure skill acquisition) and DROP (which tests a model’s reasoning over chunks of text). As we’ve written about before, the usefulness — and validity — of these benchmarks is up for debate. But for better or worse, they remain one of the few standardized ways by which AI players like Meta evaluate their models.
Llama 3 8B bests other open source models like Mistral’s Mistral 7B and Google’s Gemma 7B, both of which contain 7 billion parameters, on at least nine benchmarks: MMLU, ARC, DROP, GPQA (a set of biology-, physics- and chemistry-related questions), HumanEval (a code generation test), GSM-8K (math word problems), MATH (another mathematics benchmark), AGIEval (a problem-solving test set) and BIG-Bench Hard (a commonsense reasoning evaluation).
Now, Mistral 7B and Gemma 7B aren’t exactly on the bleeding edge (Mistral 7B was released last September), and in a few of benchmarks Meta cites, Llama 3 8B scores only a few percentage points higher than either. But Meta also makes the claim that the larger-parameter-count Llama 3 model, Llama 3 70B, is competitive with flagship generative AI models including Gemini 1.5 Pro, the latest in Google’s Gemini series.
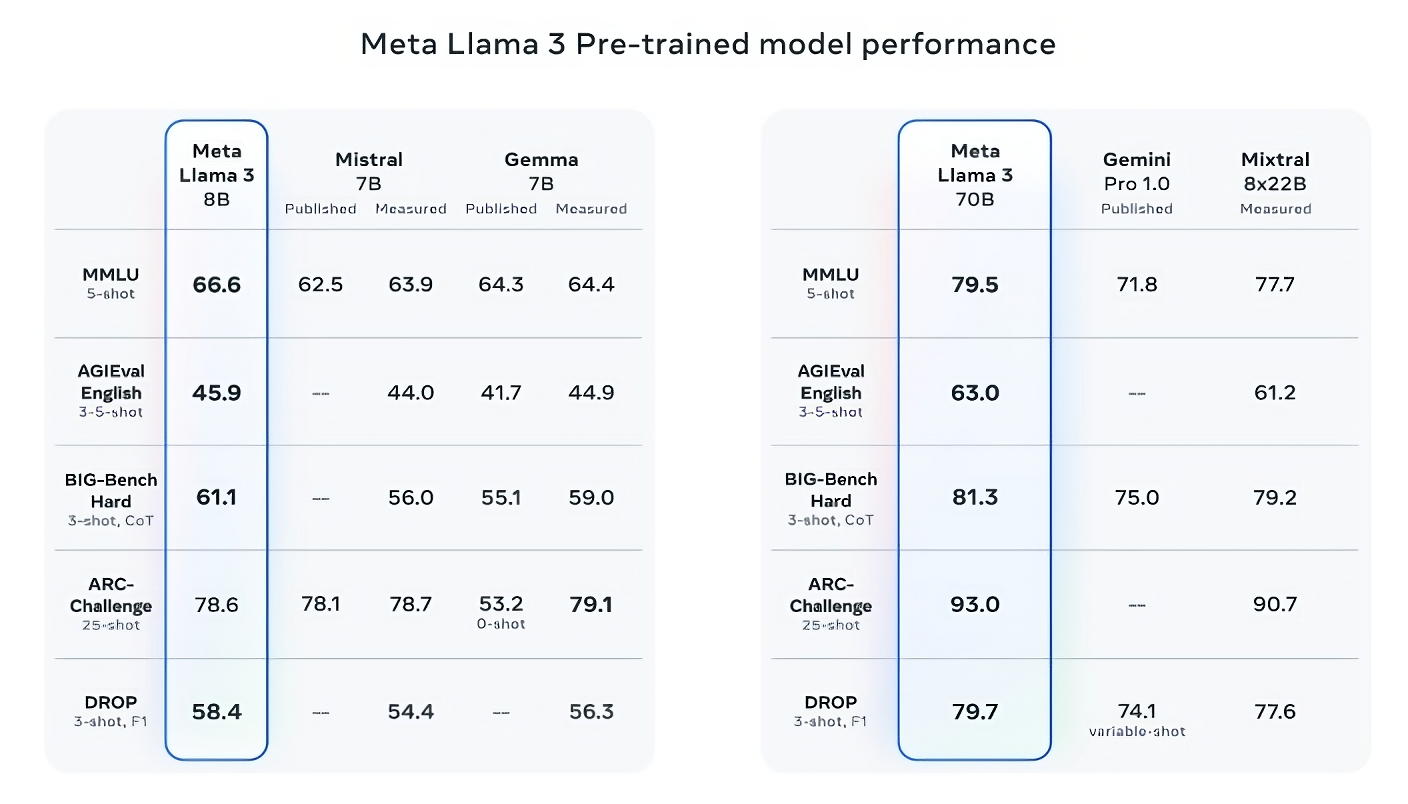
Image Credits: Meta
Llama 3 70B beats Gemini 1.5 Pro on MMLU, HumanEval and GSM-8K, and — while it doesn’t rival Anthropic’s most performant model, Claude 3 Opus — Llama 3 70B scores better than the weakest model in the Claude 3 series, Claude 3 Sonnet, on five benchmarks (MMLU, GPQA, HumanEval, GSM-8K and MATH).
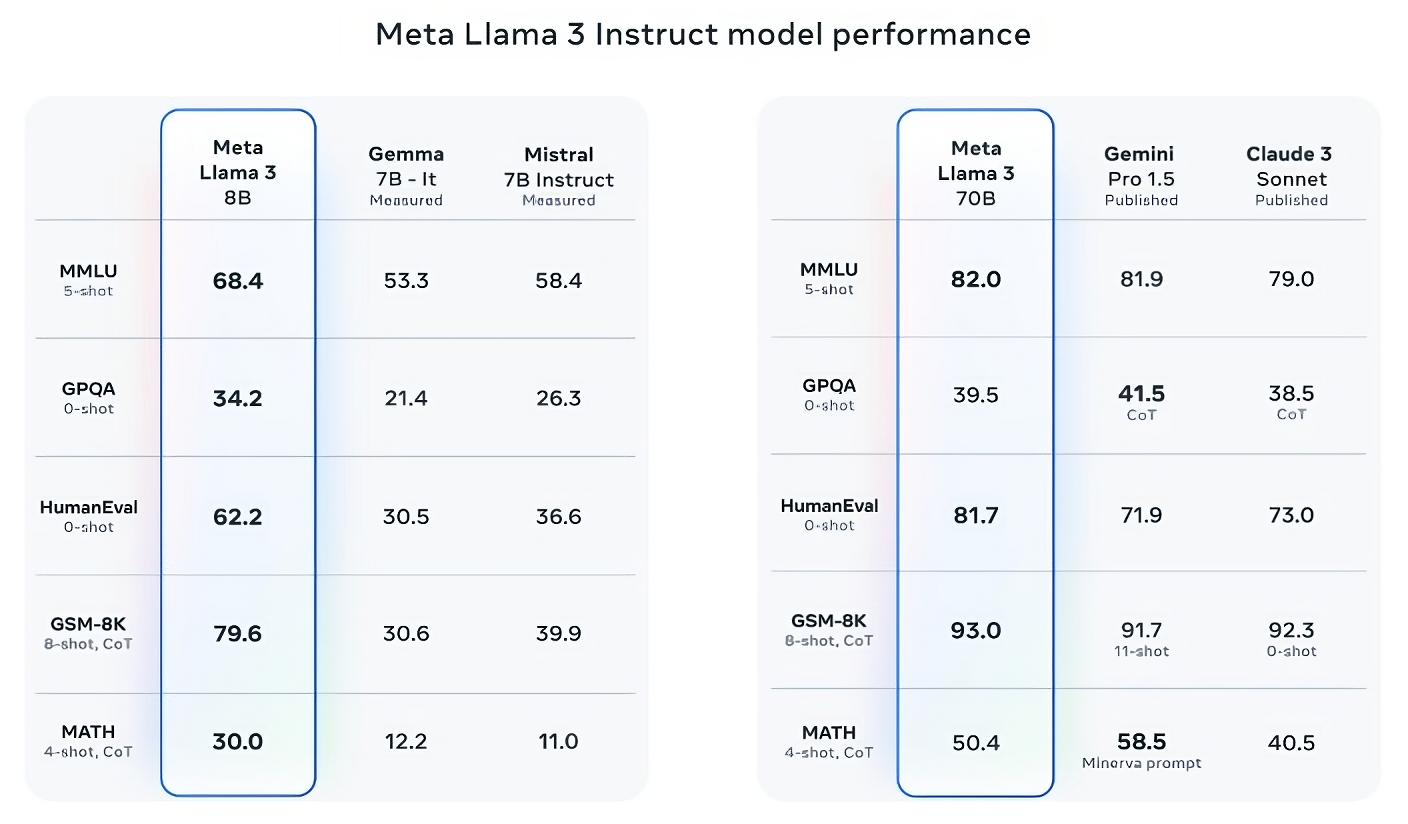
Image Credits: Meta
For what it’s worth, Meta also developed its own test set covering use cases ranging from coding and creating writing to reasoning to summarization, and — surprise! — Llama 3 70B came out on top against Mistral’s Mistral Medium model, OpenAI’s GPT-3.5 and Claude Sonnet. Meta says that it gated its modeling teams from accessing the set to maintain objectivity, but obviously — given that Meta itself devised the test — the results have to be taken with a grain of salt.

Image Credits: Meta
More qualitatively, Meta says that users of the new Llama models should expect more “steerability,” a lower likelihood to refuse to answer questions, and higher accuracy on trivia questions, questions pertaining to history and STEM fields such as engineering and science and general coding recommendations. That’s in part thanks to a much larger data set: a collection of 15 trillion tokens, or a mind-boggling ~750,000,000,000 words — seven times the size of the Llama 2 training set. (In the AI field, “tokens” refers to subdivided bits of raw data, like the syllables “fan,” “tas” and “tic” in the word “fantastic.”)
Where did this data come from? Good question. Meta wouldn’t say, revealing only that it drew from “publicly available sources,” included four times more code than in the Llama 2 training data set, and that 5% of that set has non-English data (in ~30 languages) to improve performance on languages other than English. Meta also said it used synthetic data — i.e. AI-generated data — to create longer documents for the Llama 3 models to train on, a somewhat controversial approach due to the potential performance drawbacks.
“While the models we’re releasing today are only fine tuned for English outputs, the increased data diversity helps the models better recognize nuances and patterns, and perform strongly across a variety of tasks,” Meta writes in a blog post shared with TechCrunch.
Many generative AI vendors see training data as a competitive advantage and thus keep it and info pertaining to it close to the chest. But training data details are also a potential source of IP-related lawsuits, another disincentive to reveal much. Recent reporting revealed that Meta, in its quest to maintain pace with AI rivals, at one point used copyrighted ebooks for AI training despite the company’s own lawyers’ warnings; Meta and OpenAI are the subject of an ongoing lawsuit brought by authors including comedian Sarah Silverman over the vendors’ alleged unauthorized use of copyrighted data for training.
So what about toxicity and bias, two other common problems with generative AI models (including Llama 2)? Does Llama 3 improve in those areas? Yes, claims Meta.
Meta says that it developed new data-filtering pipelines to boost the quality of its model training data, and that it’s updated its pair of generative AI safety suites, Llama Guard and CybersecEval, to attempt to prevent the misuse of and unwanted text generations from Llama 3 models and others. The company’s also releasing a new tool, Code Shield, designed to detect code from generative AI models that might introduce security vulnerabilities.
Filtering isn’t foolproof, though — and tools like Llama Guard, CybersecEval and Code Shield only go so far. (See: Llama 2’s tendency to make up answers to questions and leak private health and financial information.) We’ll have to wait and see how the Llama 3 models perform in the wild, inclusive of testing from academics on alternative benchmarks.
Meta says that the Llama 3 models — which are available for download now, and powering Meta’s Meta AI assistant on Facebook, Instagram, WhatsApp, Messenger and the web — will soon be hosted in managed form across a wide range of cloud platforms including AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM’s WatsonX, Microsoft Azure, Nvidia’s NIM and Snowflake. In the future, versions of the models optimized for hardware from AMD, AWS, Dell, Intel, Nvidia and Qualcomm will also be made available.
And more capable models are on the horizon.
Meta says that it’s currently training Llama 3 models over 400 billion parameters in size — models with the ability to “converse in multiple languages,” take more data in and understand images and other modalities as well as text, which would bring the Llama 3 series in line with open releases like Hugging Face’s Idefics2.

Image Credits: Meta
“Our goal in the near future is to make Llama 3 multilingual and multimodal, have longer context and continue to improve overall performance across core [large language model] capabilities such as reasoning and coding,” Meta writes in a blog post. “There’s a lot more to come.”
Indeed.